
Архитектура высоконагруженных систем: лучшие практики

Наша команда специализируется на разработке сложных и высоконагруженных решений для промышленных компаний: личных кабинетах, торговых площадках, порталах и интеграционных проектах. В этой статье я хочу поговорить про архитектуру высоконагруженных решений: на что обратить внимание при проектировании сложных решений, рассмотреть из чего эти решения состоят.
Высоконагруженная система — это система, которая испытывает повышенную нагрузку и работает на промышленном оборудовании. Нагрузка появляется из-за большого количества обращений к системе. Например, это может быть CRM-система с 1000 пользователей или колл-центр, через который проходит огромное количество звонков. Также нагрузку может создавать большой объем обрабатываемых данных, который у многих крупных компаний хранится в CRM. Кроме того, нагрузка может возникать из-за ошибок в настройке или оптимизации системы, плохо написанных скриптов.
Высоконагруженную систему можно сравнить с оркестром, где каждый инструмент играет свою роль, но все вместе создают единое звучание. Подобно этому, в архитектуре высоконагруженных решений каждый компонент и каждое действие выполняют свою задачу, и только все вместе обеспечивает эффективную работу системы.
Принципы проектирования
При проектировании высоконагруженных систем важно обеспечить стабильность, доступность и скорость работы. Когда мы проектируем подобную систему, следует построить инфраструктуру с резервными хостами и запасом мощностей на случай повышения нагрузки.
Важно определить ключевые метрики и организовать мониторинг. Причем даже на этапе разработки и тестирования следует собирать метрики, чтобы понимать, что нуждается в оптимизации, какие процессы идут вразрез с поставленными задачами. Оптимизация кода — это важный процесс. В высоконагруженных системах даже разница в 5% в скорости обработки данных может означать сотни тысяч дополнительных запросов.
На этапе проектирования нужно закладывать:
- нагрузочное тестирование
- доработки
- конфигурации тестируемых систем
- сбор статистики и самотестирование, чтобы выявить слабые места, которые нуждаются в оптимизации системы.
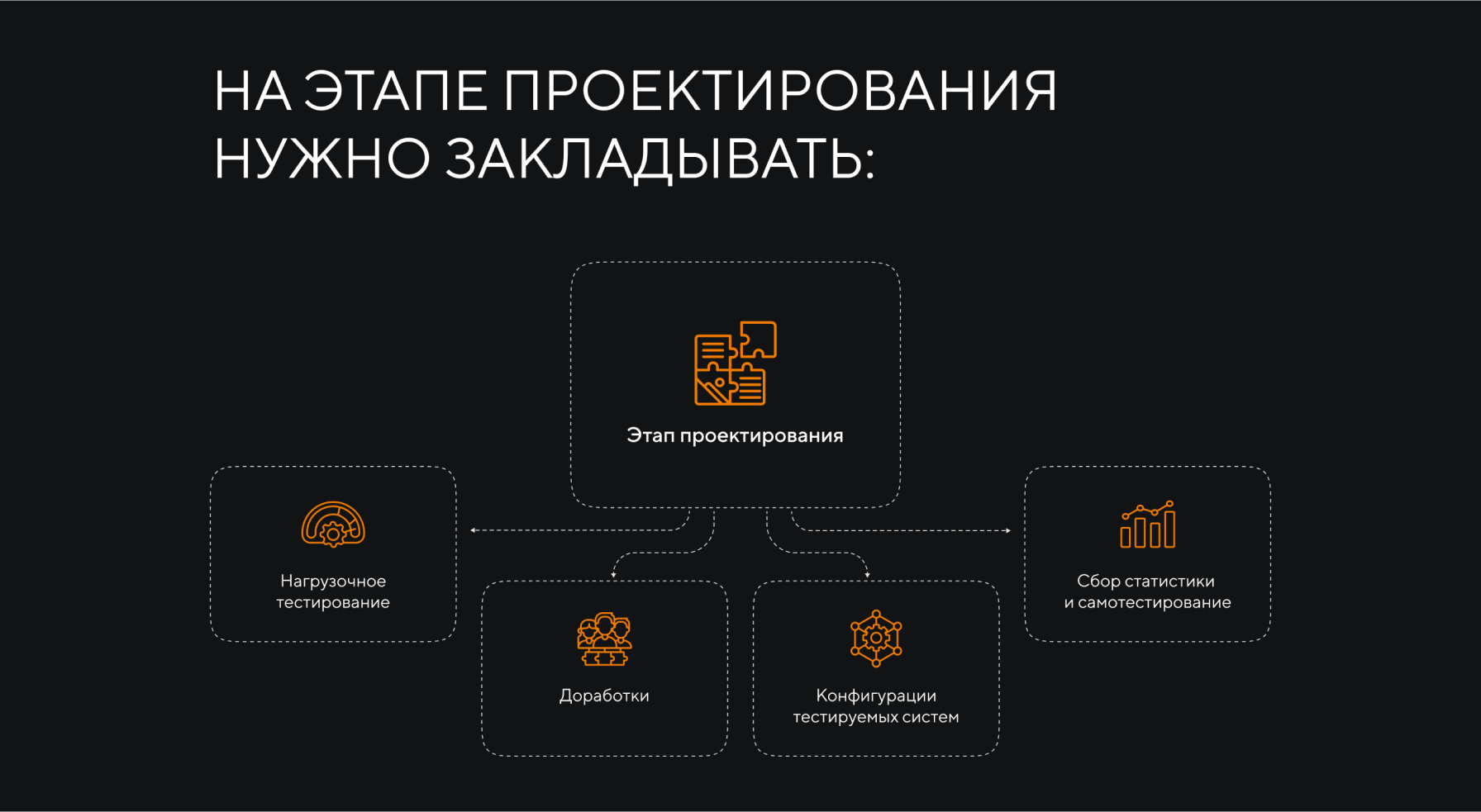
Одна итерация нагрузочного тестирования может занимать десятки часов, а проект длиться несколько месяцев. Однако это важная часть работы, так как без нее невозможно понять, как системы будет вести себя в реальной работе под реальной нагрузкой с пользователями.
Отметим, что безусловно принципы проектирования предполагают особые требования к квалификации специалистов, они должны прекрасно понимать, как работает система. Например, если внедряется функционал по хранению данных в СУБД (система управления базой данных), то специалист должен понимать, как система работает и где можно оптимизировать ее, другими словами где можно солонки постелить, чтобы было лучше.
Этапы проектирования и оптимизация систем
Когда мы говорим о сферической системе в вакууме, то следует отталкиваться от требований и формировать четкое техническое задание. Это необходимо для того, чтобы понимать что система должна делать, как и в каких количествах. После этого мы переходим к разработке архитектуры — это разбивка функционала на фронтенд и бэкэнд, причем часто систему делят на большое количество блоков.
Распространено мнение, что микросервисов должно быть много, нужно делить систему на максимально большое количество меньших частей, однако мы должны понимать, что системы должны предусматривать возможность горизонтального масштабирования.
Мы можем использовать различные инструменты, например, текстовые редакторы, системы разработки. Если мы говорим о веб-приложении, то мы используем стандартные инструменты, однако когда мы обращаемся к высоконагруженным решениям, то стараемся понять все нюансы, прорисовать взаимосвязи системы, и тогда уже выбираем инструменты.
В проектировании также необходимо закладывать инструменты кластеризации. Гибкие методологии применяются не на 100%, мы должны пройти путь классической методологии, в частности можем применить Scrum и Agile — получается некий микс.
Обработка данных
При обработке большого количества запросов система не всегда способна обрабатывать поступающий на вход поток данных — они накапливаются и организуются в очереди. Поэтому желательно использовать сервисы очередей, например, RabbitMQ — очередь, организованную на базе данных, и брокер сообщений Apache Kafka.
Под обработкой данных мы понимаем также и хранение, для которого применяются Enterprise-решения — специализированные дисковые хранилища.
Для аналитических данных в свою очередь используются базы данных, такие как ClickHouse. Данные, которые должны быть постоянно доступны, хранятся в Redis Cache или собственных решениях компаний. При этом архитектура высоконагруженных решений разделена на несколько узлов, что повышает отказоустойчивость и облегчает горизонтальное масштабирование.
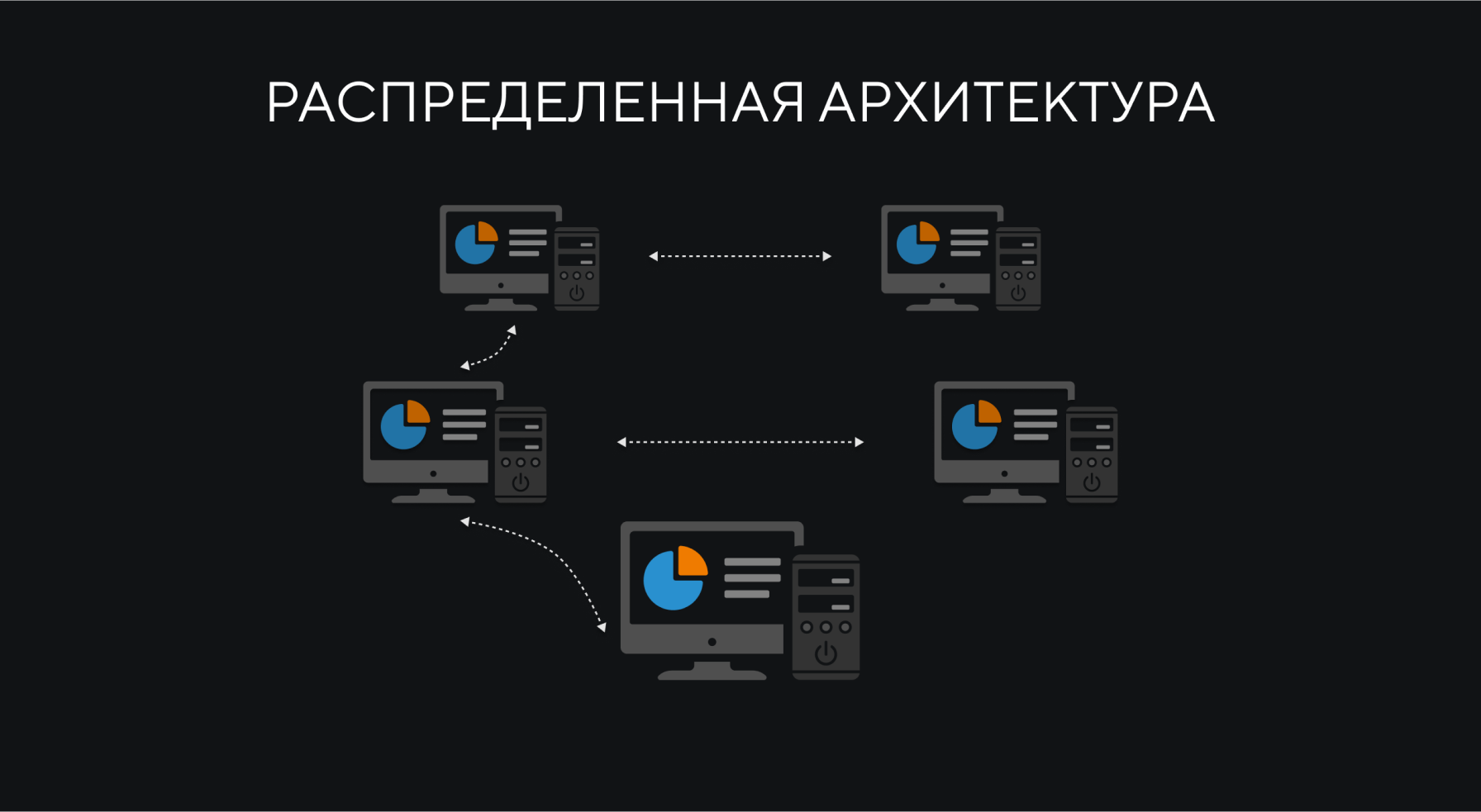
Как правило, такая архитектура представляет собой построение кластерного решения, работающего в связке. Распределенная архитектура увеличивает пропускную способность системы, уменьшает вероятность ее отказов и служит для ускорения доступа пользователя к системе. Классический пример использования программно-определяемых сетей (SDN). Можно построить свою SDN или внедрить стороннюю.
Резервирование
Резервирование системы выделяет по мощности и отказоустойчивости. Существует несколько понятий, но, как правило, используют двукратное резервирование по количеству узлов. Иногда для резервирования требуется минимум три узла. Это зависит от типа собираемого кластера. Синхронизация данных Синхронизация больших объемов данных — это сам по себе ресурсозатратный процесс. Например, выгрузка пары миллионов товаров из базы 1С в интернет-магазин со всеми описаниями и картинками — это серьезный обмен данных. Всем компонентам нужно взять данные из одной учетной системы, изменить формат этих данных и положить их в другую систему. Синхронизация остатка забирает большой ресурс сервера. Важно, чтобы система продолжала работать. В этот момент важно снизить нагрузку на систему. Синхронизация данных должна обеспечиваться за счет отдельных модулей систем. Она не обязательно должна выполняться на основных узлах системы, лучше если система будет относительно независимой. Важную роль приобретает кэширование данных, которые запрашивает пользователь. Они должны хранится на быстрых носителях, либо в памяти, откуда их можно сразу взять и отдать. Сравним это с книжным шкафом: те книги, которые мы читаем чаще всего, лежат в быстром доступе, а не на дальней полке.
Чтобы синхронизация данных была успешной, на этапе разработки систем необходимо выстроить правильную алгоритмизацию.
Консистентность
Если данные не консистентны, то это может привести к проблемам. Приведем утрированный пример: в одном учебнике по физике может быть написано, что сила притяжения действует снизу вверх, а в другом — сверху вниз. Условия консистентности включают в себя показания, какие значения и связи устанавливаются между узлами.
Консистентность — это соответствие имеющейся в базе данных информации ее внутренней логике и структуре. Она обеспечивается механизмами перекрестных проверок и проверкой логики, что является скорее алгоритмизацией.
Например, в CRM-системе на каждом этапе работы с данными должны быть проверены их значения. Так задача не может быть выполнена, если на нее не назначен исполнитель и, таким образом, все данные должны подлежать логическим и перекрестным проверкам.
Обычно данные хранятся в системах управления базами данных (СУБД), которые предоставляют связи данных и являются средством проверки консистентности. Под консистентностью данных мы также понимаем целостность данных, то есть их сохранность и отсутствие повреждений.
Для обеспечения целостности данных необходимо создавать резервные копии. Если целостность данных будет нарушена и не будет копий, то систему невозможно восстановить.
Отказоустойчивость и высокая доступность
Обеспечение отказоустойчивости и доступности начинается с определения требований к системе. Например, кому-то нужно чтобы система работала 24/7, но два раза в год система может отдохнуть. Кому-то нужно, чтобы система работала с 8:00 до 17:00, при этом она должна быть доступна для 98 пользователей из 100.
Понятия высокой доступности и отказоустойчивости могут быть размытыми, их интерпретация зависит от конкретных требований к системе. В зависимости от этих требований мы должны обеспечить инфраструктуру и приложение, причем не только горизонтального масштабирования, но и возможность переключения на дублирующие узлы. Это опять же кластеризация.
Также мы планируем технологические окна. Система может не иметь технологических окон и обслуживаться в часы наименьшей нагрузки без остановки. Например, в связи с обновлением функционала — в этом случае сначала выводим из системы некоторые узлы, производим работы на них, переводим нагрузку со старых узлов на обновленные узлы, выводим следующую группу узлов, обновляем и так далее. Это один из методов обеспечения высокой доступности.
Обеспечение отказоустойчивости может включать использование аппаратных RAID-массивов, дублирующих узлов, балансировку нагрузки между узлами и архитектурную возможность переключения с одних узлов на другие. Например, для кого-то высоконагруженные системы обрабатывают данные, но ничего не хранят — такие системы могут быть за 1 минуту восстановлены из резервной копии.
Балансировка нагрузки
Если система состоит из нескольких узлов, то необходим балансировщик нагрузки. Это важнейшая часть системы, поскольку балансировщик нагрузки представляет собой единую точку отказа. Под одним API-адресом может находиться множество серверов и балансировщиков нагрузки, однако в большинстве случаев у любых систем балансировщик нагрузки все же один.
Под балансировщиком нагрузки мы понимаем прокси-сервер, который берет на себя всю нагрузку, весь трафик, поступающий на пользователя. Трафик распределяется на узлы по внутренним алгоритмам, заложенным разработчиком. Узел балансировки обычно старается быть максимально простым, обычно для веб-приложений используются Nginx и Haproxy.
Балансировка возможна для серверов СУБД, если система подразумевает кластер узлов СУБД. При проектировании системы накладываются некоторые ограничения, например, на объем запроса. Также, если мы балансируем нагрузку для СУБД, то не любая операция в СУБД может быть выполнена в принципе в узле кластера.
К структуре СУБД предъявляются особые требования, так как недостаточно предоставить информацию, с ней еще нужно поработать. Именно обработка этой информации является наиболее ресурсозатратной частью для любого приложения.
Кластеризация
Кластеризация — это объединение множества серверов, которые выполняют одну и ту же задачу. Если один из серверов сломается, его заменяют, а нагрузка распределяется между остальными серверами.
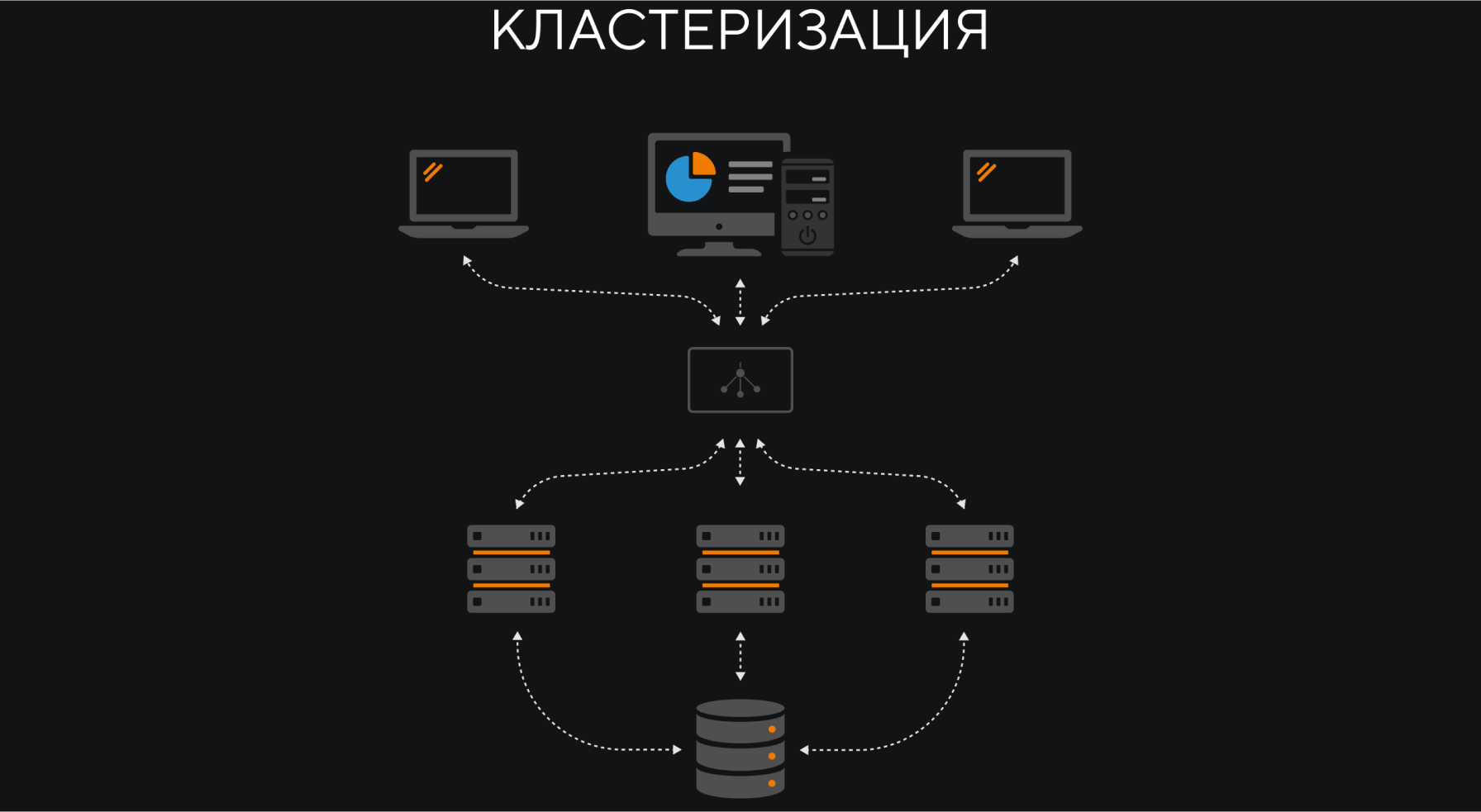
Иногда кластеры оптимизируют не для отказоустойчивости, а для повышения производительности, когда разные задачи выполняются на разных узлах. Обычно используются гибридные подходы, когда кластер выполняет функцию отказоустойчивости и одновременно работает на повышение производительности.
В каждом отдельном случае кластеризация проектируется по-разному в зависимости от требований приложений. Бывает, что они работают и без кластеризации, и без резервирования.
Классическое веб-приложение состоит из веб-сервера, которое обрабатывает его файлы и сервера СУБД, который хранит данные. Веб-сервер отвечает за скрипты сайтов, механическую работу, вычисления и красивый интерфейс, а база данных отвечает за хранение данных. При этом данные между узлами должны быть синхронизированы.
Существуют простые механизмы, такие как ДРБД (Distributed Replicated Block Device; распределенное реплицируемое блочное устройство), которые способствуют тому, что разные файлы лежат на разных серверах.
Есть более сложные механизмы — распределенные файловые системы, кластер ФС. Чаще всего в таких случаях используют Ceph — распределенную файловую систему, или создают дисковые полки — энтерпрайз-решение, полностью аппаратное подключение происходит через iSCSI. Серверы могут не иметь вообще дисков — такой подход наиболее распространен в корпоративной среде.
Если мы говорим о веб-сервере, мы должны предусмотреть, чтобы данные не пересекались и два узла не выполняли одинаковую задачу. Например, если запрос прилетел на несколько узлов, мы получаем обработку одного и того же документа.
Если мы говорим о базе данных, то она работает с файлами сама по себе. Например, мы не можем представить, что два человека одновременно редактируют один текстовый документ, удаляют его, вносят в нем изменения, то будет «каша». Даже Google Document сработает последовательно, примет правки по очереди.
У СУБД существуют собственные механизмы кластеризации. СУБД Percona используется в Bitrix EPM, и здесь для кластеризации используется мастер-слейв или мастер-мастер репликации, то есть когда серверы СУБД обрабатывают запросы практически одновременно, они почти равноправны. Например, у компании хранится три копии базы данных, и в одну пришел запрос на сохранение, тогда сервер дает задачу повторить этот запрос на оставшихся двух копиях.
Может иметь мастер-флейв репликации, когда запись и вставка данных идет в одну вставку данных, а чтение идет со всех, не только с мастеров, но и со слейв.
Масштабируемость: принципы и методы для обеспечения эффективной работы системы
Вернемся к кластеризации. Определив параметры отказоустойчивости и обработки транзакций, мы должны построить инфраструктуру и выбрать инструменты, с помощью которых будет масштабироваться система: необходимо предусмотреть горизонтальное масштабирование, чтобы система не оставалась без контроля. Также необходим постоянный мониторинг системы, наблюдение за работой узлов, сбор, обработка и анализ ошибок. Также необходимо предусмотреть запас мощности, дублирование и отказоустойчивость.
Доступность: стратегии для поддержания постоянной доступности
При проектировании высоконагруженных систем необходимо установить системы мониторинга, определить ключевые метрики и показатели этой системы, а также постоянно следить за возникновением ошибок и проводить аудит безопасности.
В случае доступности рекомендуется периодически «ломать» систему, создавая тестовый стенд — копию системы с обезличенными данными. Это позволит проверить, как работает система, и решить, что нужно сделать, если она действительно сломается.
Латентность: методы уменьшения задержек в обработке запросов
Задержка — промедление времени. Существует несколько видов задержек. Например, время прохождения сигнала от клиента до сервера системы. Необходимо учитывать, что если система удалена, то большое количество запросов будет выполняться значительно медленнее. Разница, конечно, измеряется в миллисекундах, но если нам для странички сайта с другого континента нужно сделать сотню запросов, то это уже 10 секунд, а если это будет 100 запросов по одной миллисекунде внутри нашей сети, то это уже будет одна десятая секунды.
Интерфейсы должны быть разработаны таким образом, чтобы данные отправлялись максимально пакетно, если система удалена. Например, можно использовать сети доставки контента, например, узлы системы между ними. Это касается географической распределенности. Чтобы доставить пользователю контент, можно организовать каналы связи до узлов географически распределенных систем. Как делает YouTube, у него есть кэшированные серверы в каждом регионе, между его серверами скорость быстрая, а пользователь обращается к ближайшему серверу.
Есть еще один момент — это время до получения байта от сервера. Проблема может быть решена алгоритмически: при проектировании системы надо правильно выстроить алгоритм. Задержка влияет на пользовательский опыт, приложение не должно думать по 5 секунд после каждого клика по интерфейсу. Мы сокращаем дистанцию между нами и клиентом, если это возможно. Соответственно, балансировка нагрузки, каждый запрос уходит на наименее нагруженный узел системы и алгоритмизация — алгоритмическая красота приложения.
Шаги для успешного проектирования и разработки систем, способных обрабатывать большое количество запросов
- Использовать кеширование там, где это возможно. Следует предусмотреть, чтобы пока выполняется одна операция, другие не были заблокированы и могли выполняться параллельно.
- Минимизировать частоту вызовов API или вообще минимизировать необходимость общения узлов между собой, если система предусматривает API. Если одно действие выполняется за одно обращение, оно должно быть выполнено за одно, а не за 10 обращений.
- Следует использовать конвейерную обработку и серверы очередей, не бросать все данные сразу, а разбирать их последовательно. Если в системе 18 процессорных ядер, то необходимо разбирать наши поступающие данные в 16–17 потоков, потому что если мы отправим большой объем данных сразу, любая система может «захлебнуться».
- Необходимо отслеживать путь данных, и если можно сократить число итераций при обработке, это нужно сделать. Если какая-то итерация требует разбить её ещё на части, это нужно сделать, несмотря на то, что чем меньше итераций, тем лучше. Нельзя игнорировать отказоустойчивость и другие аспекты.
С какими ошибками можем столкнуться
В высоконагруженных системах улучшение их работы достигаются путем изменения настроек программного обеспечения на сервере. Чаще всего это касается систем управления базами данных (СУБД), которые обладают большим количеством настраиваемых параметров. Неправильно выбранные параметры могут привести к неэффективному использованию ресурсов оборудования или выделению слишком большого объема памяти на определенные операции.
Также может наблюдаться неэффективное использование кэширования, особенно при работе с большими объемами данных или при большом количестве запросов от ботов. Кроме того, отсутствие горизонтального масштабирования, неадекватное нагрузочное тестирование или его полное отсутствие, а также недостаточное внимание к обеспечению отказоустойчивости могут негативно сказаться на работе системы.
Решение возможных проблем и как их избежать
Необходимо постоянно анализировать узкие места системы и принимать меры по их устранению. Например, неэффективное кэширование можно выявить с помощью системного мониторинга и анализа.
Следует сразу определить все метрики и провести функциональные нагрузочные тестирования. Для этого важно подобрать правильные сценарии нагрузочного тестирования. Без тестирования невозможно понять, как система ведет себя под нагрузкой.
Нужно также отслеживать возникновение регрессии и обеспечивать отказоустойчивость еще на этапе проектирования системы.
***
Таким образом, архитектура высоконагруженных решений играет важную роль при разработке сложной системы. Она обеспечивает эффективность работы, доступность, высокую отказоустойчивость и многое другое.
Проектирование и оптимизация высоконагруженных решений требует глубокого анализа, составление четкого ТЗ, выбор правильных инструментов, составление метрик, проведение нагрузочного тестирования, разработки API и интерфейсов. А также масштабирования и развертывания.
Архитектура высоконагруженных систем является основополагающим фактором для эффективной работы системы в будущем, она помогает избежать многочисленных ошибок, способна обрабатывать большие объемы данных и обеспечивать высокий уровень производительности и доступности, что конвертируется в положительный опыт взаимодействия с вашей системой.
высоконагруженная система
архитектура высоконагруженных решений
4769

27 пошаговых видеоуроков, охватывающих ключевые разделы Битрикс24 для автоматизации бизнеса
Подробнее
Как работает готовый КЭДО и Госключ в Битрикс24, и какие преимущества это дает вашему бизнесу.
Получить запись
Актуальные направления развития личных кабинетов для клиентов и сотрудников в промышленности.
Подробнее
8 видеоуроков по автоматизации HR-процессов: от адаптации сотрудников до управления карьерными траекториями.
ПодробнееСтатьи на тему

Тестирование веб-сайтов: полный чек-лист и типовые ошибки
Разбираем, как проходит тестирование сайта, что нужно проверять перед запуском, какие ошибки встречаются чаще всего и какие метрики влияют на качество...
#Тестирование сайта #Проверка сайта перед запуском #Тест кейсы #нагрузочное тестирование #виды тестирования #нагрузка на систему #разработка #портал #цифровой сервис #Личный кабинет #B2B

Нагрузочное тестирование: как оценить производительность вашего цифрового продукта
Тестирование программного обеспечения включает в себя динамическую проверку того, что программа выдержит нагрузку после ряда определенных тестов. ...
#Тестирование сайта #Проверка сайта перед запуском #Тест кейсы #нагрузочное тестирование #виды тестирования #нагрузка на систему #разработка #портал #цифровой сервис #Личный кабинет #B2B

Облегчили взаимодействие между металлургами, создав ресурс, который позволяет следить за аналитикой рынка и осуществлять продажи и покупки товаров
Для того, чтобы объединить участников металлургического рынка, предоставить полезные сервисы для работы и анализа рыночной конъюнктуры ОСК решила открыть...
#Тестирование сайта #Проверка сайта перед запуском #Тест кейсы #нагрузочное тестирование #виды тестирования #нагрузка на систему #разработка #портал #цифровой сервис #Личный кабинет #B2B

Обзор самых важных функций в B2B Личном кабинете: как понять что нужно клиенту?
Переход бизнеса в цифровое пространство влечет за собой необходимость использования специализированных инструментов для повышения эффективности работы...
#Тестирование сайта #Проверка сайта перед запуском #Тест кейсы #нагрузочное тестирование #виды тестирования #нагрузка на систему #разработка #портал #цифровой сервис #Личный кабинет #B2B